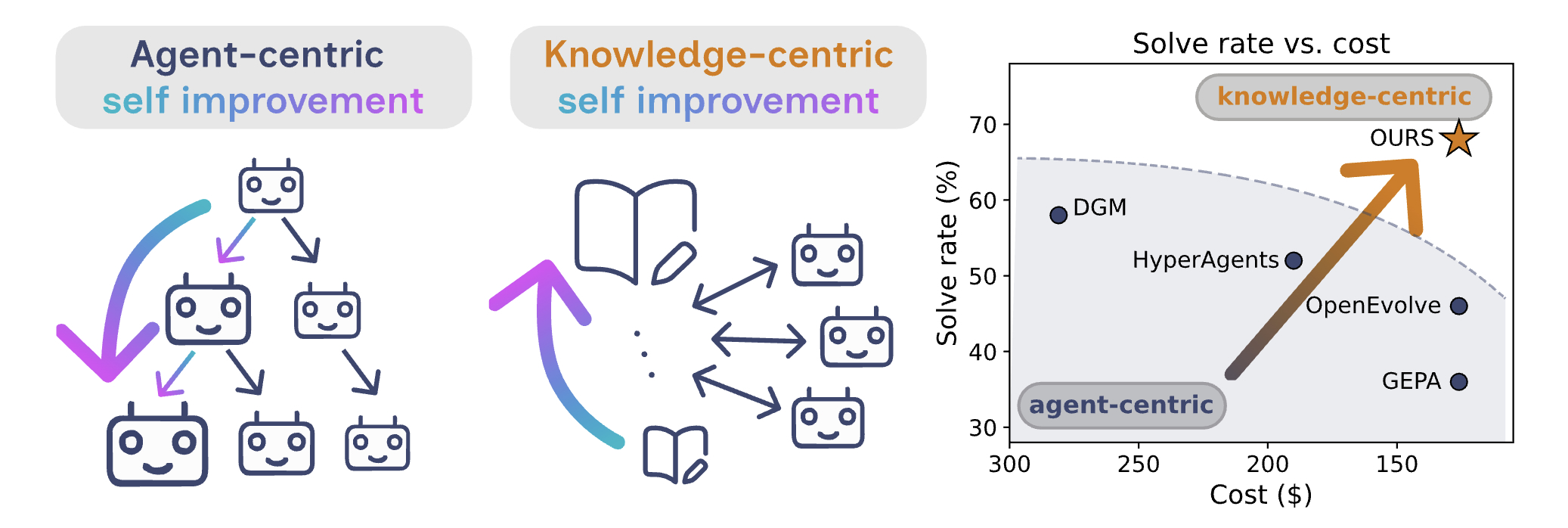
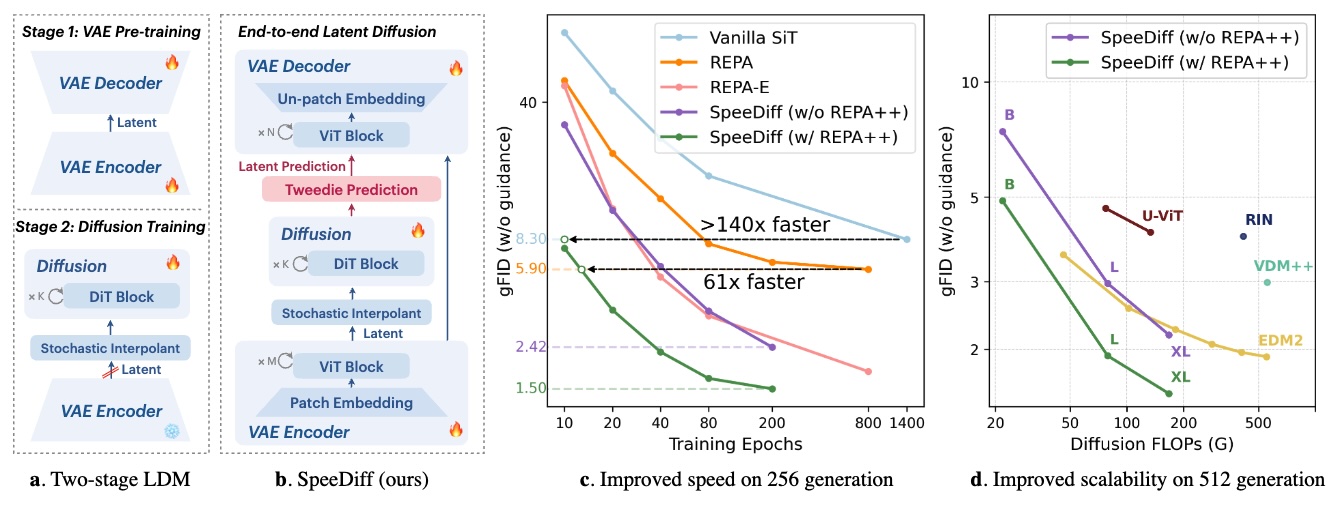
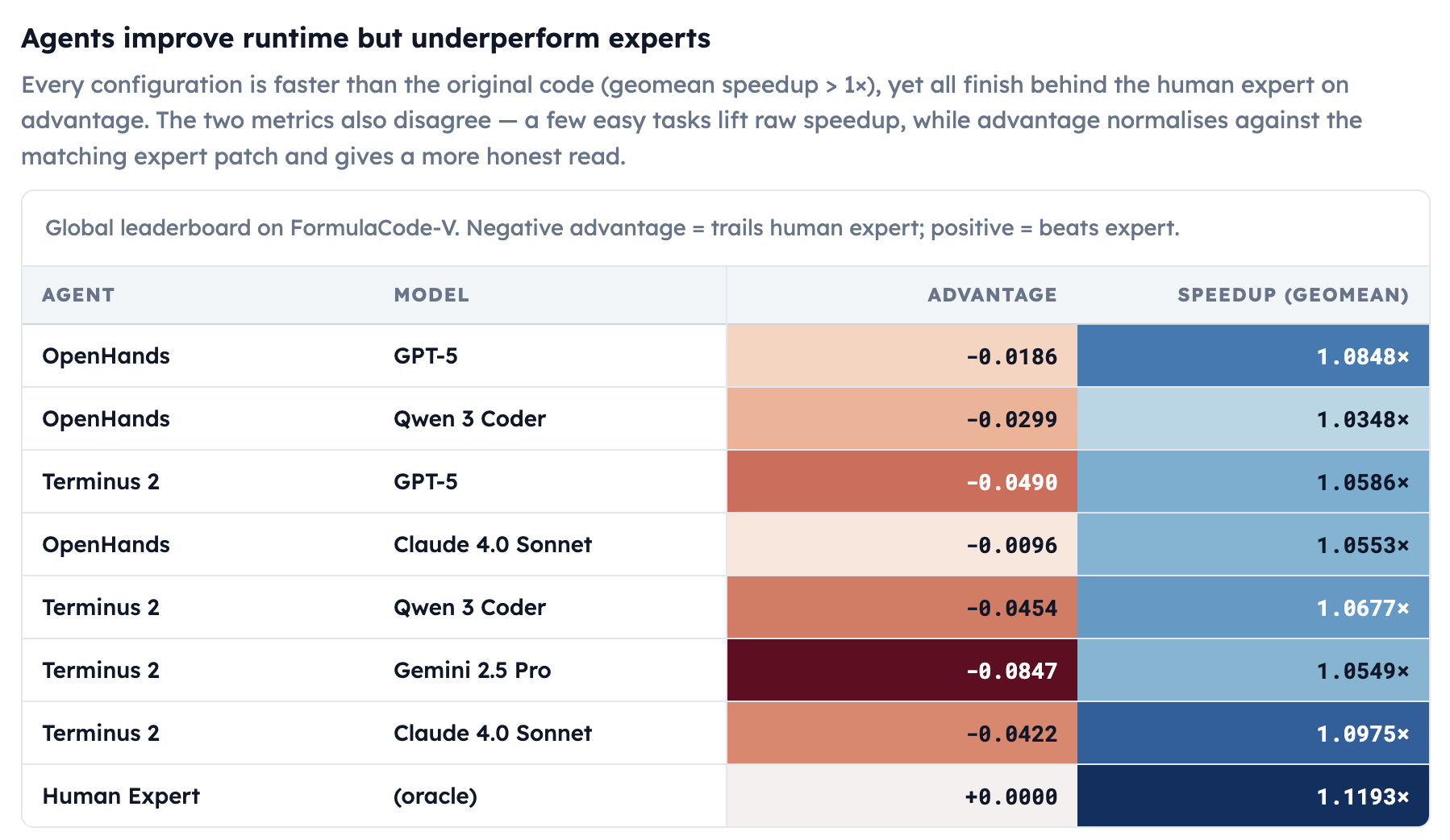
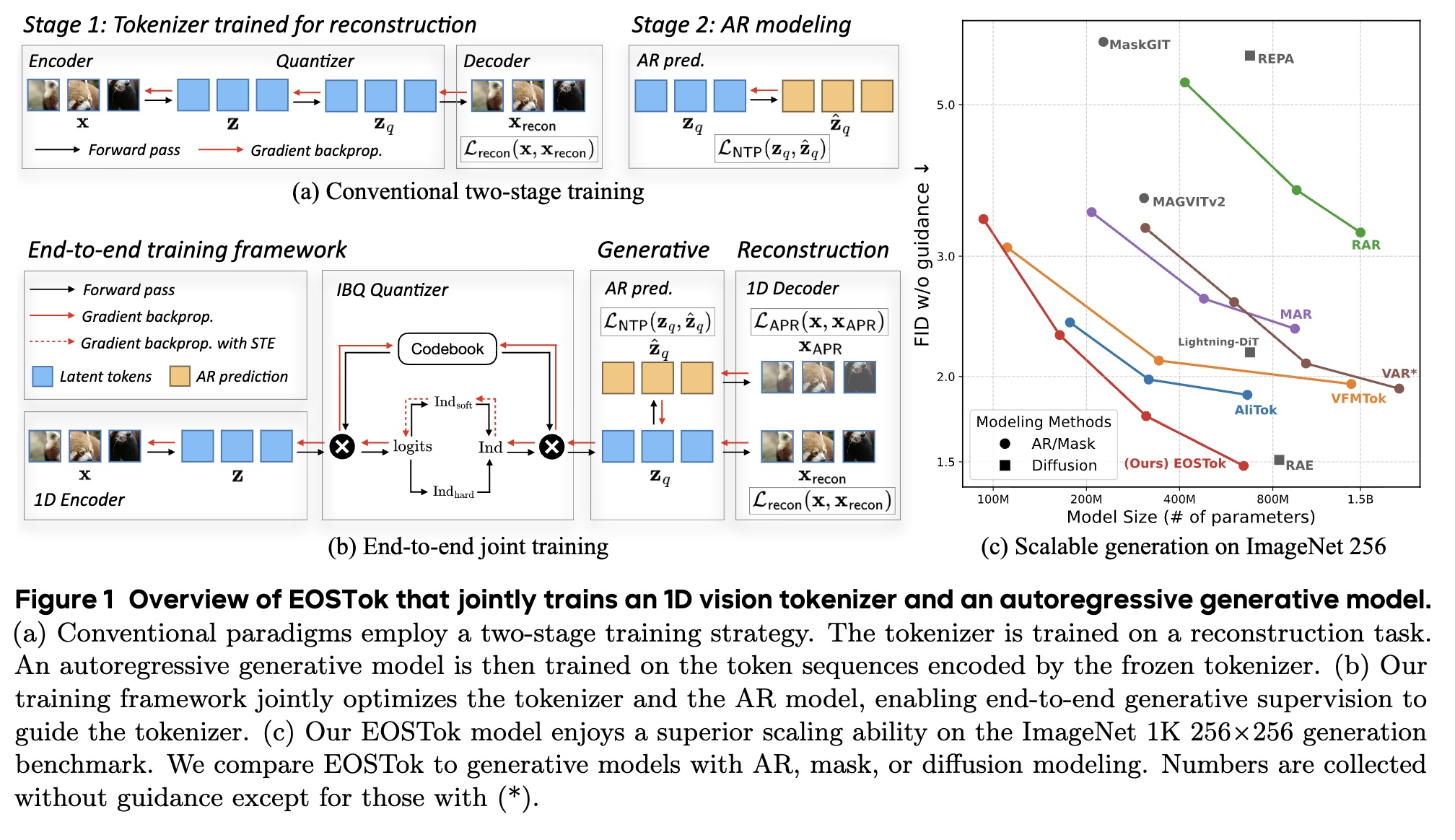
About Me
Professor of Computing and Mathematical Sciences at Caltech.
Research Interests: Machine Learning and Artificial Intelligence.
Industry Advising: Asari AI, Cainex, Latitude AI, Lila Sciences, and Tera AI.
ICLR Leadership: Member of ICLR Board. General Chair of ICLR 2025. Senior Program Chair of ICLR 2024.